Is udpipe your new NLP processor for Tokenization, Parts of Speech Tagging, Lemmatization and Dependency Parsing
If you work on natural language processing in a day-to-day setting which involves statistical engineering, at a certain timepoint you need to process your text with a number of text mining procedures of which the following ones are steps you must do before you can get usefull information about your text
- Tokenisation (splitting your full text in words/terms)
- Parts of Speech (POS) tagging (assigning each word a syntactical tag like is the word a verb/noun/adverb/number/...)
- Lemmatisation (a lemma means that the term we "are" is replaced by the verb to "be", more information: https://en.wikipedia.org/wiki/Lemmatisation)
- Dependency Parsing (finding relationships between, namely between "head" words and words which modify those heads, allowing you to look to words which are maybe far away from each other in the raw text but influence each other)
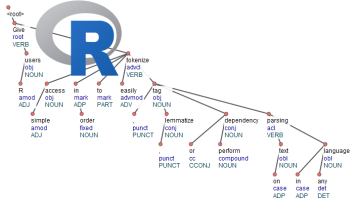
If you do this in R, there aren't much available tools to do this. In fact there are none which
- do this for multiple language
- do not depend on external software dependencies (java/python)
- which also allow you to train your own parsing & tagging models.
Except R package udpipe (https://github.com/bnosac/udpipe, https://CRAN.R-project.org/package=udpipe) which satisfies these 3 criteria.
If you are interested in doing the annotation, pre-trained models are available for 50 languages (see ?udpipe_download_model) for details. Let's show how this works on some Dutch text and what you get of of this.
library(udpipe)dl <- udpipe_download_model(language = "dutch")dl
language file_model dutch C:/Users/Jan/Dropbox/Work/RForgeBNOSAC/BNOSAC/udpipe/dutch-ud-2.0-170801.udpipe
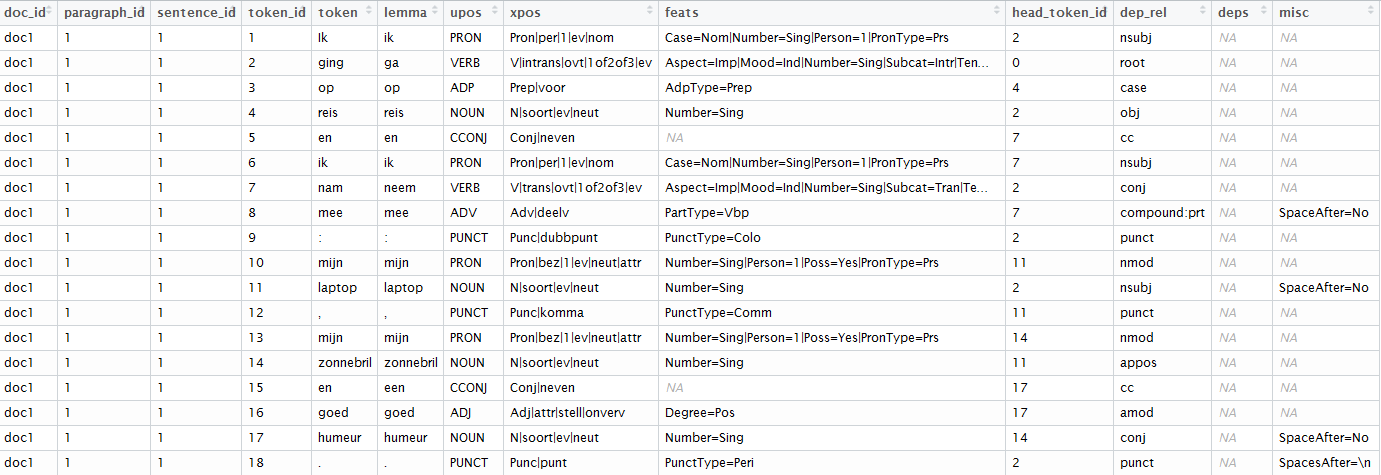
udmodel_dutch <- udpipe_load_model(file = "dutch-ud-2.0-170801.udpipe")x <- udpipe_annotate(udmodel_dutch, x = "Ik ging op reis en ik nam mee: mijn laptop, mijn zonnebril en goed humeur.")x <- as.data.frame(x)x
The result of this is a dataset where text has been splitted in paragraphs, sentences, words, words are replaced by their lemma (ging > ga, nam > neem), you get the universal parts of speech tags, detailed parts of speech tags, you get features of the word and with the head_token_id we see which words are influencing other words in the text as well as the dependency relationship between these words.
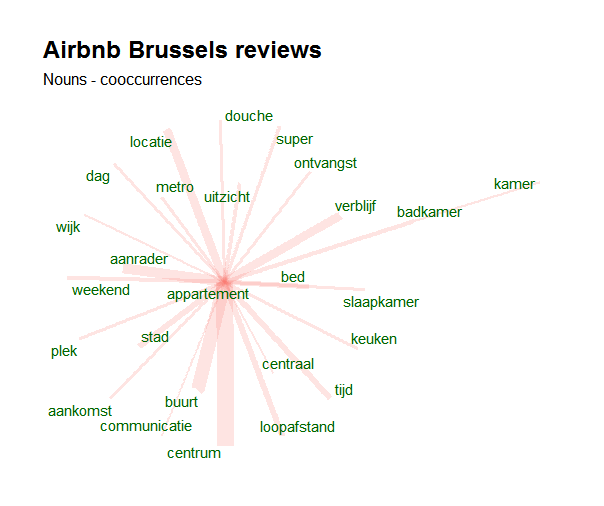
To go from that dataset to meaningfull visualisations like this one is than just a matter of a few lines of code. The following visualisation shows the co-occurrence of nouns with customer feedback on Airbnb appartment stays in Brussels (open data available at http://insideairbnb.com/get-the-data.html).
In a next post, we'll show how to train your own tagging models.
If you like this type of analysis or if you are interested in text mining with R, we have 3 upcoming courses planned on text mining. Feel free to register at the following links.
- 18-19/10/2017: Statistical machine learning with R. Leuven (Belgium). Subscribe here
- 08+10/11/2017: Text mining with R. Leuven (Belgium). Subscribe here
- 27-28/11/2017: Text mining with R. Brussels (Belgium). http://di-academy.com/bootcamp + send mail to This email address is being protected from spambots. You need JavaScript enabled to view it.
- 19-20/12/2017: Applied spatial modelling with R. Leuven (Belgium). Subscribe here
- 20-21/02/2018: Advanced R programming. Leuven (Belgium). Subscribe here
- 08-09/03/2018: Computer Vision with R and Python. Leuven (Belgium). Subscribe here
- 22-23/03/2018: Text Mining with R. Leuven (Belgium). Subscribe here
For business questions on text mining, feel free to contact BNOSAC by sending us a mail here.