Big Data
Clients typically come to us in order to integrate advanced analytics inside big data platforms. or in order to give them architectural advice in the use of advanced analytics tools (R/Python/Spark) inside big data tools (Spark / HAWQ / Hadoop). Some clients understand big data, others are just beginners. To us big data is a tool, advanced analytics are the techniques which we consider as regular statistical services.
Before we show our reference architecture and some basic advise, as the big data ecosystem is quite large, below we give an overview of the SQL and NoSQL ecosystem for R users. Contact us for more detailed insights.
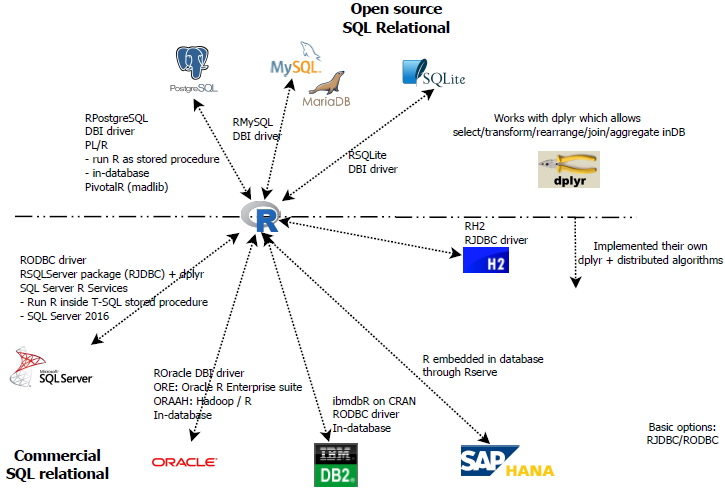
SQL Ecosystem
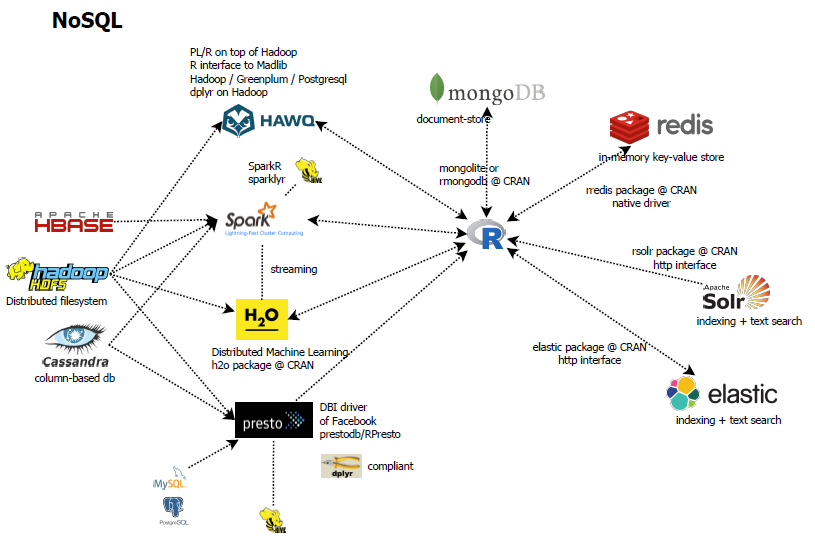
NoSQL ecosystem
Our big data architecture
When setting up a complete enterprise analytical architecture, our reference architecture is below. We like to give you more details in a face to face meeting. Contact us for more detailed insights.
Part of our reference architecture, the following components are supported during our big data projects.
Oracle R Enterprise expertise
We provide support for Oracle R Enterprise and Oracle R Enterprise for Hadoop jointly with our partner Tripwire Solutions. Contact us for more information.
![]()
Spark expertise
We provide support for building modelling pipelines on top of Spark by using R and Python. For sparklyr we even have an R package on called spark.sas7bdat on CRAN. Contact us for more project-specific information.
![]()
HAWQ, Greenplum and PostgreSQL expertise
During several of our projects, we have usedthe PL/R + PL/Python extensions on top of PostgreSQL complient databases, allowing to run advanced analytics on top of Hadoop (HAWQ) as well as traditional PostgreSQL of the massively parrallel database Greenplum. Contact us for more detailed insights.
|
|
|
|
Architectural advise
As advanced analytics experts, we provide also architectural advise for the use of R and Python on top of big data tools. More information is provided during a face-to-face meeting. Contact us here.
Training
We want you to use big data in-house so if you have data scientists at your site, we train them. We give training in big data using open source tools. This training covers the following topics.
- Overview of the big data ecosystem for data scientists
- Linux system commands for data scientists
- Work with the hadoop file system (read/write, directories). Typical Hadoop files
- Map-Reduce & mapply
- Spark & R: SparkSQL using package sparklyr & dplyr. Spark Machine Learning using package sparklyr (data preparation, regression, randomforest & boosted trees) + spark extensions
- HAWQ & R: Running PL/R stored procedures using Apache HAWQ. Classification & regression using MadLib & PivotalR
More information can be found here.