Text Analytics
Text Mining has become quite mainstream nowadays as the tools to make a reasonable text analysis are ready to be exploited and give astoundingly nice and reasonable results. At BNOSAC, we have used it mainly for text mining on call center logs, salesforce data, emails, HR reviews, IT logged tickets, customer reviews, survey feedback and many more. We help companies get a competitive edge by providing text analytics using our proven methodology and our web app txtminer. Interested? Get in touch.
Application Domains
Typical application domains for which we executed projects are
1 Understanding what is written in text by identifying topics/client issues.
2 Enriching predictive models (churn / upsell) with text analytics
3 Process efficiency gains by better email redirection or reducing IT handling times
4 Building a FAQ list + automatic replies to client emails including matched solutions from FAQ questions
5 Automatic solving of client issues
6 Extracting structured content from text, pdf files or websites
txtminer
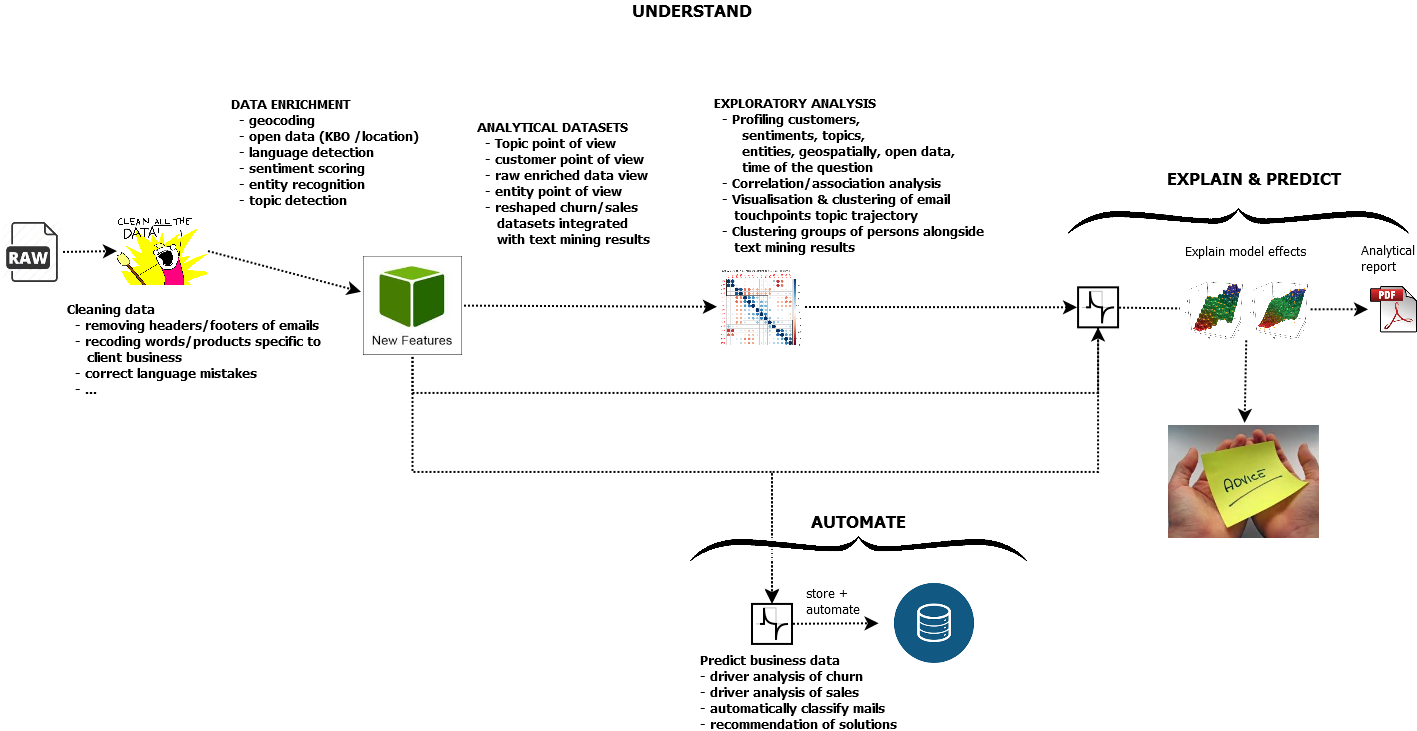
Our text mining methodology
A typical text mining project consists of executing a number of steps which are detailed below.
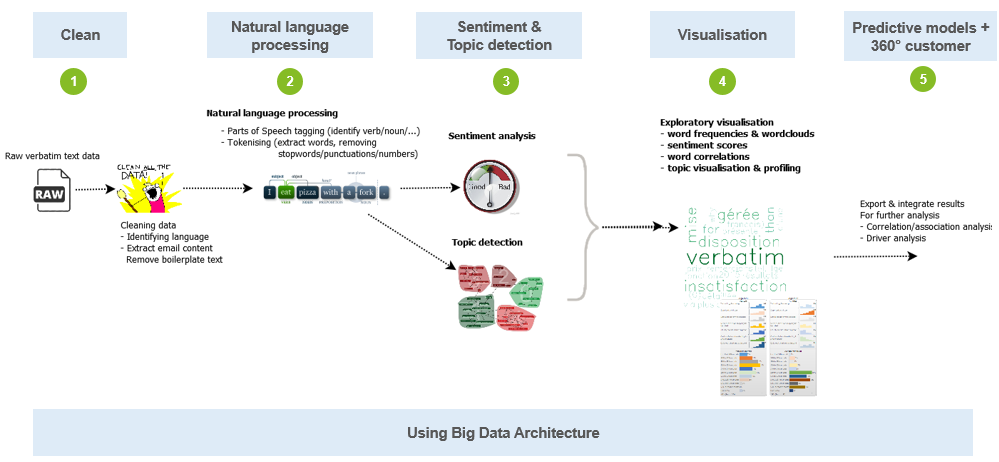
Text analytics steps
1 A first step consists of cleaning the data. Making sure we retain only relevant text. The more structured your text data is already about a specific topic, the better the results will be.
2 Next we perform Natural Language Processing. This means we identify words and label if the word is a noun/verb/adverb/ or if it is a person, a city, a number or a specific object.
3 In the subsequent step we identify sentiment scores and topics in the text.
4 The results are visualised extensively and reported. This is core to understanding the topics and having a dialogue with business users.
5 The text analytics enrichments are next used for other purposes like predictive modelling, automatic replies, better forwarding, creating of FAQ lists, ...
6 The process is automated.
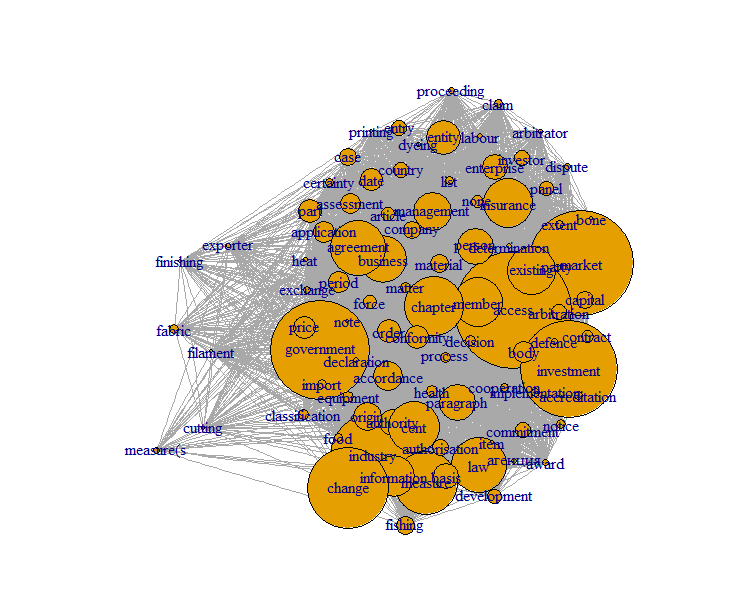
Visualisation is key
Visualisation is key during text analytics. Some sample visualisation of typical text mining results can be found below. For reason of confidentiality these were executed on the open CETA trade agreement instead of showing the client results.
|
|
|
|
|
|
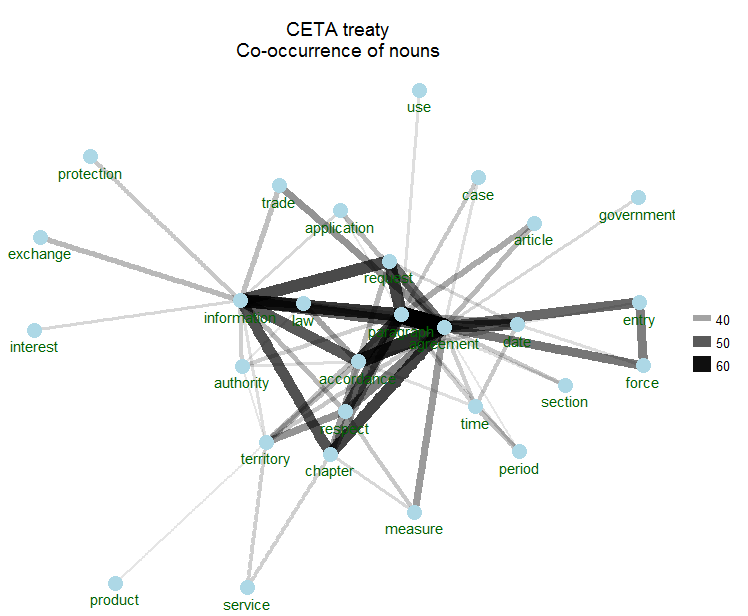
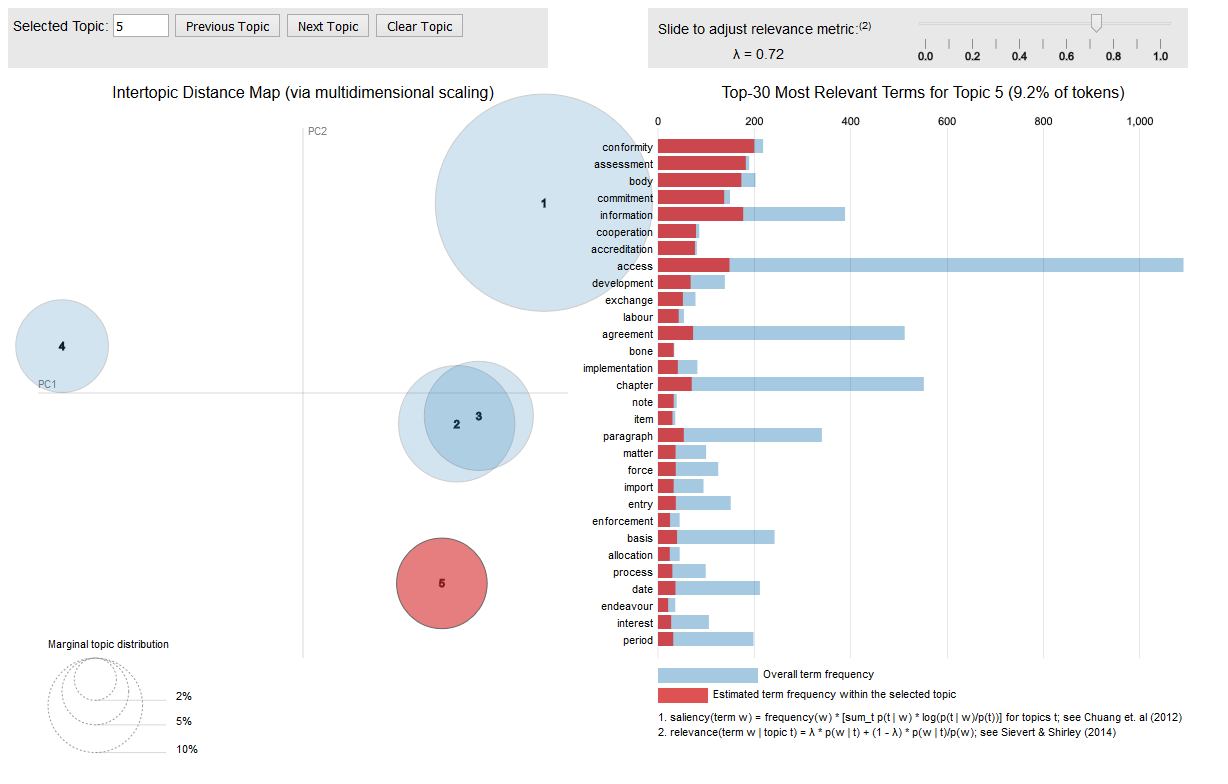
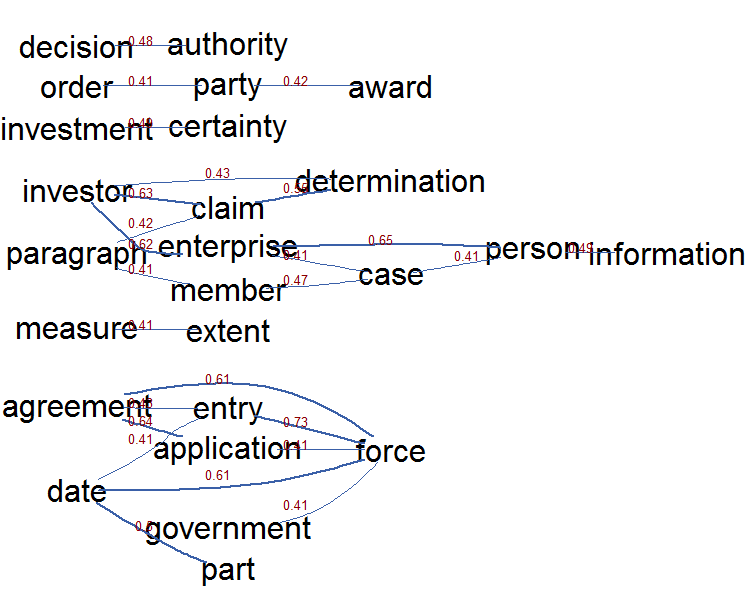

Automation is key
A next step next to understanding what is written is performing predictive modelling and giving suggestions for process improvements and responses to clients. Automation is always a part of our text mining proposal.
Training
We want you to use the techniques in-house so if you have data scientists at your site, we train them. We give training in text mining using open source tools. This training covers the following topics.
- Text encodings
- Cleaning of text data, regular expressions
- String distances
- Graphical displays of text data
- Natural language processing: stemming, parts-of-speech tagging, tokenization, lemmatisation
- Sentiment analysis
- Statistical topic detection modelling and visualization (latent diriclet allocation)
- Visualisation of correlations & topics
- Word embeddings
- Document similarities & Text alignment
More information can be found here.